Introduction
Imagine your AI-powered support system routes a high-priority customer ticket to the wrong team. Your fraud detection model misses a pattern it should have caught. Your autonomous diagnostic pipeline reports normal battery performance on a cell that is trending toward failure.
The model did not break. No alert fired. No pipeline errored out. Everything looked fine.
This is the silent data gap problem. And it is one of the most dangerous failure modes in production AI systems because it doesn't look like a failure at all.
The problem
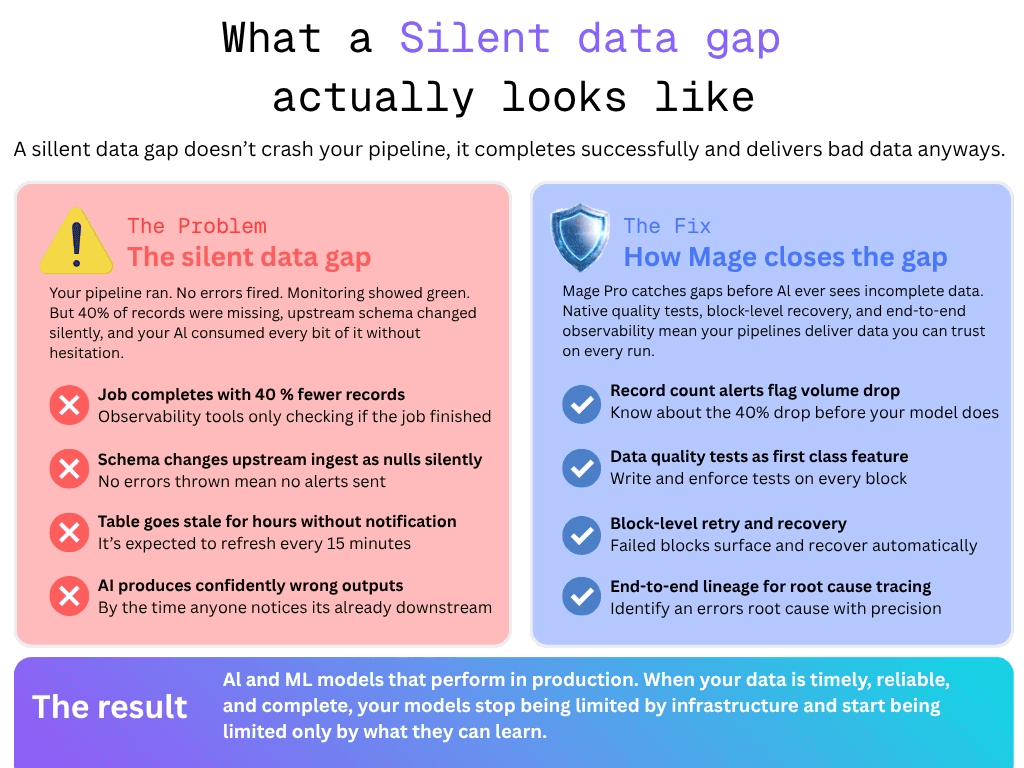
A silent data gap is not a crashed pipeline. It is a pipeline that ran successfully, completed without errors, and delivered data downstream. The only problem is, and it's a big problem, that data was incomplete, stale or missing records nobody noticed. And the worst part is, AI doesn't care, it's going to make a decision based on whatever data is available.
Traditional analytics systems make data gaps visible. Downstream users may identify a chart with extreme outliers, dashboards with null values, or reports that don't make sense. These are points where failures can be caught. Engineers are notified, they investigate the issue, and fix it.
AI systems don't necessarily work that way.
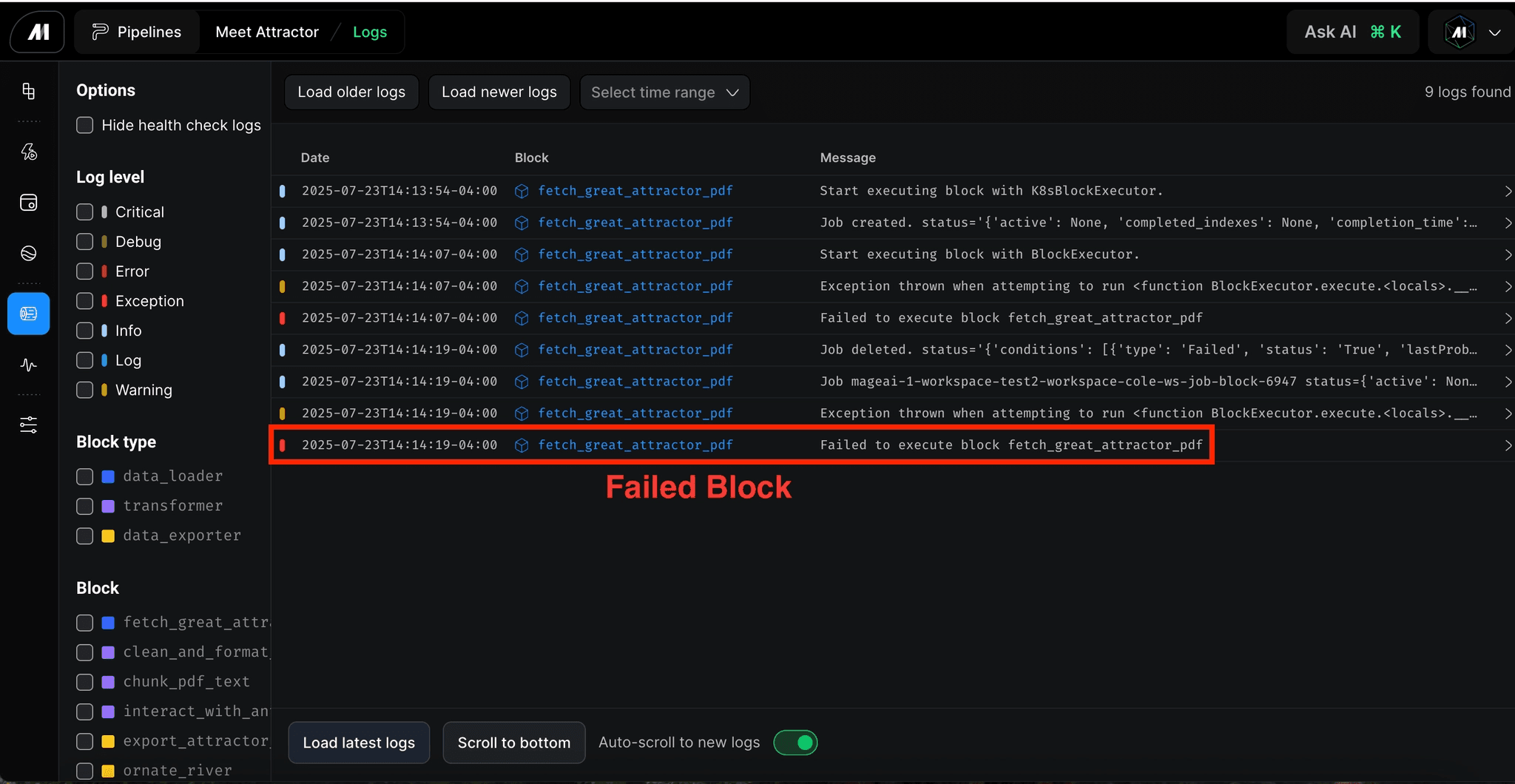
When an upstream team changes source system schema, the ingestion job may or may not throw an error. It will simply receive null values silently, and every model downstream consumes that incomplete or dirty data without knowing it. Some other failures by the source system like API rate limiting and late arriving data may also cause problems for your AI systems.
The monitoring gap makes all of this worse. Many observability tools answer one question: did the job finish? They do not alert when a job completes successfully but delivers 40% fewer records than yesterday, or when a table that refreshes every 15 minutes has not updated in two hours. You may have to find an additional tool to write tests against your data, or add great expectations tests to your workflow, which comes with its own difficulty of use.
By the time anyone notices the AI output has drifted, the bad data has already been processed, your AI has already provided an output, and tracing the root cause means working backwards through every pipeline layer manually.
How Mage Pro solves this problem
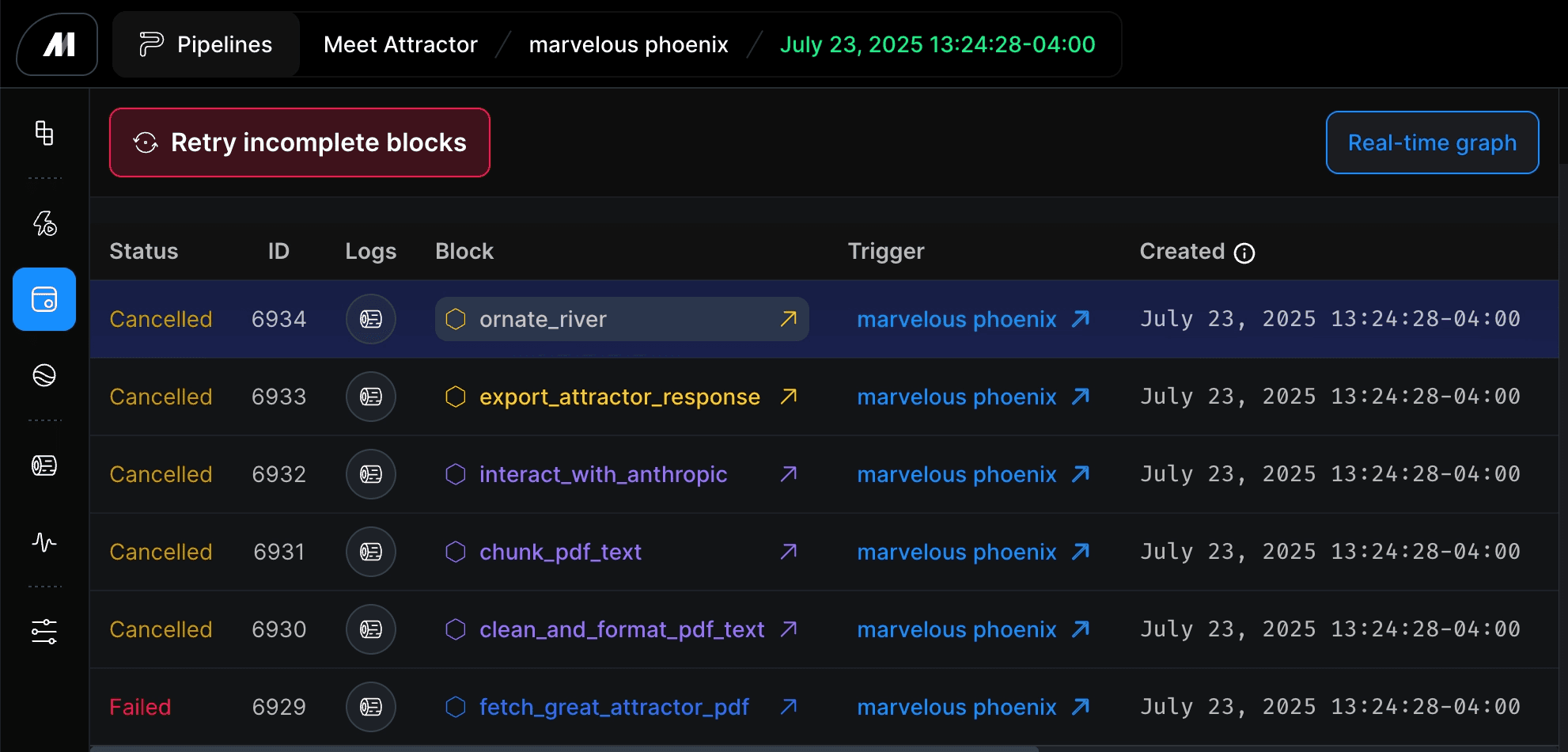
Mage is built around block-level execution, which means every step in a pipeline runs, reports, and can be monitored independently. When something goes wrong at a specific transformation or ingestion step, it surfaces at that block rather than propagating silently into downstream outputs. Engineers see exactly where the failure happened, what data was affected, and what needs to be rerun. All of this can be done without having to trace back through the entire project and is identified at the block level.
Beyond failure detection, Mage tracks data freshness and completeness as first-class concerns. Pipelines can be configured to alert not just on job errors but on data volume anomalies, freshness thresholds, and completeness checks at each block. The distinction matters enormously for AI workloads where a pipeline that ran is not the same as a pipeline that delivered what your model actually needs.
Block-level retry logic means that when a partial failure does occur, recovery is surgical. Rather than rerunning an entire pipeline and risk compounding the problem, engineers can rerun the specific block that failed and validate the output before it moves downstream. The result is faster recovery and fewer silent propagation failures reaching production AI systems.
The Result
When pipelines reveal failures at the point they happen, rather than letting them propagate, AI systems stop producing confidently wrong outputs. Engineering teams catch data quality issues at the pipeline layer before they ever reach a model. The feedback loop tightens. Debugging shifts from tracing why an AI output was wrong to confirming that the data feeding it was right.
The most dangerous AI failures are the ones that look like successes. Silent data gaps are an infrastructure problem, not a model problem, and teams that treat them as such build AI systems that are actually trustworthy in production.
Your AI is only as reliable as the pipeline behind it. Build accordingly.

Authors:

From Grimore to real world.
Make your data ready for AI, agents, apps, dashboards — and the actions they drive.
