TLDR
dbt and Fivetran are proven tools that have defined modern data engineering. But AI-ready data means more than clean tables in a warehouse. It means timely, relevant, and reliable data. Data can be structured and unstructured, and it should be delivered to every system that needs it. This article compares dbt + Fivetran and Mage Pro across the dimensions that matter most for teams building AI systems that depend on both kinds of data.
Table of contents
Introduction
The dbt + Fivetran combination has been a cornerstone of the modern data stack for good reason. Fivetran makes ingestion fast and manageable. dbt brings software engineering discipline to SQL transformation. Together they power analytics workflows at thousands of companies and have built a mature, well-supported ecosystem around them.
As organizations push AI into production, the scope of what counts as data expands significantly. It is no longer just structured tables in a warehouse. It is policy documents, customer support transcripts, product manuals, contracts, and internal knowledge bases. It is unstructured content that AI systems need to read, interpret, and act on just as much as they need clean analytical data.
The dbt + Fivetran stack was designed for structured, warehouse-centric workflows. That remains valuable. But when your AI systems need to consume both a customer's purchase history and the policy document that governs how to respond to their request, a warehouse-only stack leaves half your data out of reach.
What AI-ready data actually means
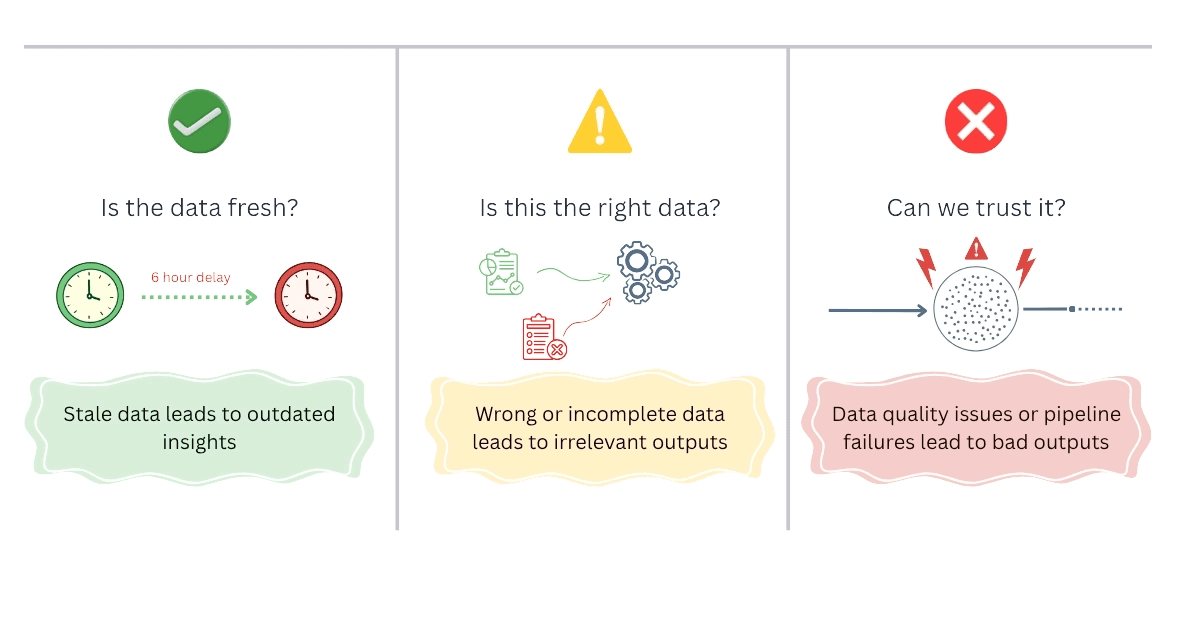
At Mage, AI-ready data comes down to three dimensions: timely, relevant, and reliable.
Timely means data is fresh enough to be useful. A model making a real-time recommendation cannot rely on data from a batch run that completed six hours ago. An AI assistant answering questions about company policy needs the current version of that document, not last quarter's.
Relevant means data is enriched, structured, and context-rich enough to give AI systems what they actually need. Raw data that happens to be available is not the same as data that has been prepared for AI consumption. This applies equally to a structured sales table and an unstructured employee handbook. All structured and unstructured data needs to be processed in a way your AI systems can access it.
Reliable means pipelines that run consistently and surface failures before bad data reaches a model. A model fed incomplete or stale data produces confidently wrong outputs. That is true whether the data is a missing row in a database table or an outdated version of a compliance document.
This framing changes how you evaluate your data stack. The question is not just whether it can move structured data from a source to a warehouse. The question is whether it can deliver timely, relevant, and reliable data of any kind to any system that needs it.
How the stacks compare
dbt and Fivetran each do their core jobs well. Fivetran handles managed ingestion from structured sources and dbt brings SQL-based transformation with version control and a solid testing framework. For analytics engineering on structured data, the combination is hard to argue with.
Where the stack shows its limits is when AI workloads enter the picture. Unstructured data such as documents, PDFs, knowledge bases, and internal files require additional tooling to bring into the pipeline. Orchestration is not native to either tool, so most teams add a third system to manage the workflow. dbt provides a strong testing framework for structured data, but tests are executed after transformations, not during ingestion. While failures are caught quickly in well-orchestrated pipelines, invalid data can still reach models before being flagged. Additionally, unstructured data pipelines sit outside of dbt entirely, leaving a gap in end-to-end data validation.
Side-by-side summary
Capability | dbt + Fivetran | Mage Pro |
|---|---|---|
Structured data ingestion | Strong | Strong |
Unstructured data ingestion | May require additional tooling | Native |
SQL transformation | Strong | Strong |
Python transformation | Limited | Native |
Native orchestration | Requires third-party | Built-in |
Streaming ingestion | Limited | Native |
Block-level data quality | Post-transformation | Throughout pipeline |
AI workload support | Requires additional tooling | Native |
End-to-end observability | Fragmented across tools | Unified |
How to think about the decision
If your team's primary focus is analytics engineering, dbt remains one of the best tools available. Combined with Fivetran's managed ingestion, it is a mature, well-supported stack with a large community behind it.
But, if you are building AI systems, this means your data stack has a new job. Your data may be structured or unstructured, and it must be timely, relevant, and reliable. That scope goes well beyond what dbt + Fivetran was designed to cover. Adding tools to fill the gaps works, but each addition is more operational overhead and another place for data quality issues to hide.
Mage Pro was built around the full definition of AI-ready data. It goes beyond just transforming and writing structured data to a warehouse. It handles any data, structured or unstructured, and prepares and delivers it in a form that AI systems can actually use.
Conclusion
AI systems are only as good as the data feeding them. That data is not just rows in a table. It is documents, policies, transcripts, and knowledge bases alongside transactional and analytical data. The stack you choose needs to make all of it timely, relevant, and reliable.
Your AI is only as reliable as the pipeline behind it. Build accordingly.
Want to see how Mage Pro handles your AI pipeline requirements? Schedule a free demo at www.mage.ai/getdemo

Authors:

From Grimore to real world.
Make your data ready for AI, agents, apps, dashboards — and the actions they drive.
