Build an AI-Powered MCP pipeline with Mage Pro - Part 1: Extract, Transform, and Structure PDF Data for AI Integration
TLDR
This article describes how to build an AI system to answer questions about the Great Attractor using Model Context Protocol (MCP). In part 1 you’ll learn how to use Mage Pro to create a data pipeline that connects knowledge sources to AI systems, including fetching PDF data, cleaning the text, and preparing it for us with Anthropic’s Claude. This approach allows for more accurate, source-specific AI responses rather than relying solely on general training data.
Introduction
Over the past few months my son became interested in Space exploration. He’s brought home various books on the Milky Way Galaxy and books about different space exploration technologies. A few days ago we watched a short video clip about the great attractor and he started asking questions I wasn’t able to answer. So I thought what the hell, let me build something that would help me come up with answers.

Meet ”Attractor”, my new MCP generated AI that will answer questions about the Great Attractor from “Evidence of the Great Attractor and Great Repeller from Artificial Neural Network Imputation of Sloan Digital Sky Survey” by Christopher Cillian O’Neill. So how did I do this? Let’s get into it.
What is Model Context Protocol?
Think of MCP as your Physics professor, when you ask it a question, it uses the knowledge available to it to answer that question. It’s the technical connector between your local knowledge systems and AI. MCP creates a bridge between source materials and AI systems. This allows applications to provide accurate, authoritative responses based on targeted information sources. It’s not just referring to general training data. With MCP your AI can finally interact with your specific knowledge assets and provide feedback and answers based only on that information. Next, we’ll create a new pipeline in Mage Pro.
Create a new pipeline
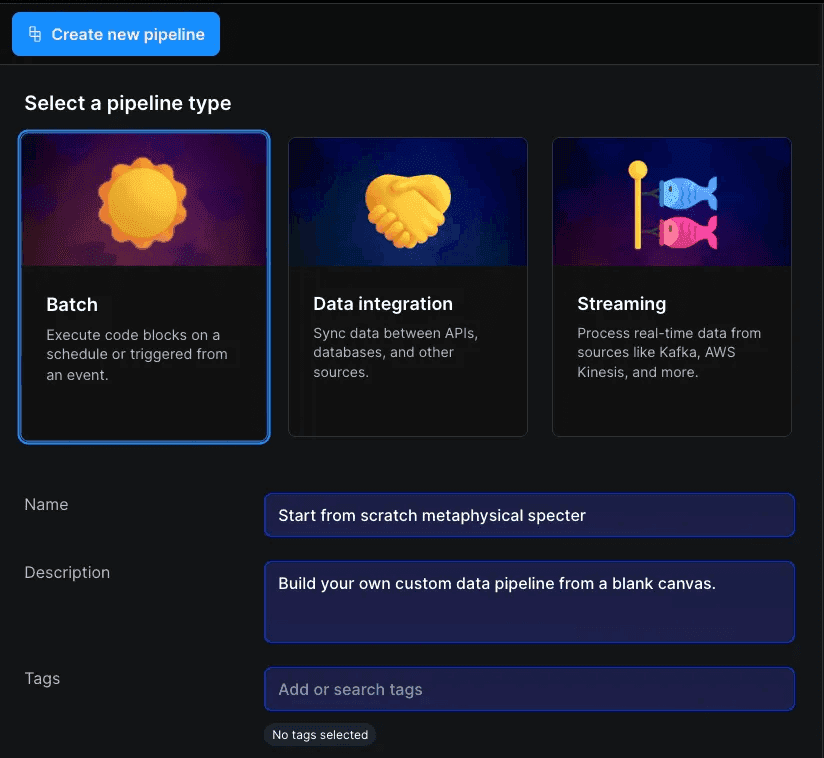
To create a new pipeline, from the Mage Pro home page hover over the left navigation pop-out menu and select “Pipelines.” Once we’re in our Mage Pro environment we’ll head over to the create pipeline page by hitting the green “New pipeline” button.

Next, we’ll create our pipeline using the UI below:
-
Select the Batch pipeline option.
-
Give the pipeline a name (mine is “Meet Attractor”)
-
Optionally provide a description for the pipeline
-
Tag the pipeline something memorable
-
Click the blue “Create new pipeline” block.
These 5 simple steps create a batch data pipeline in Mage Pro. You don’t need to write any code to do this, it’s all done within the UI. Super simple!
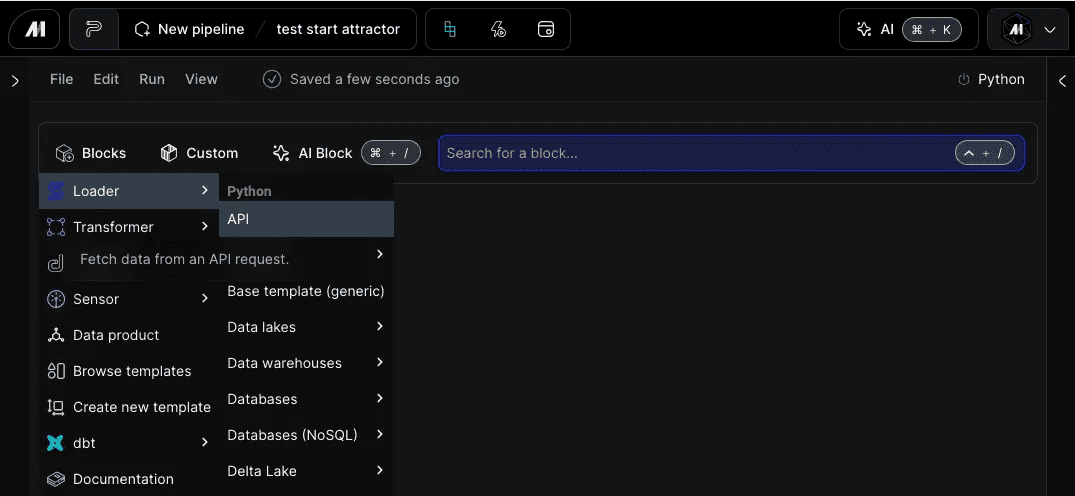
Finally, before we get into the code, let’s go over how to add a block in Mage Pro. Think of a block like a task. It’s where your code can be written in a Jupiter Notebook style environment. To create a block follow the instructions below:
-
Click the “Blocks” button
-
Hover over the “Loader” option
-
Click API
-
Give the block a name
-
Click “Save and add”
These simple steps will create a new API block template to extract data from an API or other type of URL. For our tutorial we’ll be using a Github URL to extract the content from a PDF file.
Fetch information from your knowledge systems
The data loader block fetches a PDF document from Github and transforms it into structured data. After fetching the PDF from Github it uses the PyPDF2 python library to extract the paper’s metadata and content from the document. The content is organized into a dictionary containing document details and complete text. Structuring the output as shown in the code below will serve as the foundation for the rest of the MCP pipeline.
import requests
from io import BytesIO
import PyPDF2
from datetime import datetime
@data_loader
def load_pdf_from_github(**kwargs):
# Load PDF from GitHub repository
github_pdf_url = "<https://raw.githubusercontent.com/mage-ai/datasets/master/great_attractor_pdf.pdf>"
print(f"Fetching PDF from GitHub: {github_pdf_url}")
# Download the PDF
try:
response = requests.get(github_pdf_url)
response.raise_for_status() # Ensure we got a valid response
# Read the PDF content
pdf_content = BytesIO(response.content)
pdf_reader = PyPDF2.PdfReader(pdf_content)
# Extract metadata
pdf_info = {
"title": "Evidence of the Great Attractor and Great Repeller",
"author": "Christopher C. O'Neill",
"num_pages": len(pdf_reader.pages),
"source_url": github_pdf_url,
"fetch_time": datetime.now().isoformat()
}
# Extract text from all pages
all_text = ""
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
page_text = page.extract_text()
all_text += page_text + "\\n\\n"
print(f"Successfully extracted {pdf_info['num_pages']} pages from PDF")
# Create result with both metadata and content
result = {
"metadata": pdf_info,
"content": all_text
}
return result
except Exception as e:
print(f"Error fetching PDF from GitHub: {e}")
# Instead of providing sample text, let's throw an error to ensure we don't proceed without the actual document
raise Exception(f"Failed to load PDF document: {e}")
Clean and format pdf text
The first transformation block cleans and refines the raw PDF text to improve readability and consistency. It applies regex to normalize formatting issues that are commonly found in content extracted from PDFs. It cleans multi-line breaks, hyphenated words splitting lines, and headers that repeat. The block adds structured document headers including title, author, and source information before returning the cleaned text with metadata that tracks character count and processing time.
import re
@transformer
def clean_document(data, **kwargs):
"""
Clean and format the extracted PDF text
"""
# Check if data is available
if data is None or "content" not in data:
raise Exception("No PDF content available to clean")
# Extract text and metadata from previous block
text = data["content"]
metadata = data["metadata"]
print("Cleaning document text...")
# Clean up common PDF extraction issues
# 1. Replace multiple newlines with a single newline
text = re.sub(r'\\n{3,}', '\\n\\n', text)
# 2. Fix broken words that might have been split across lines
text = re.sub(r'(\\w+)-\\n(\\w+)', r'\\1\\2', text)
# 3. Remove headers and footers that repeat on each page
text = re.sub(r'Journal of High Energy Physics,\\s+Gravitation and Cosmology.+?\\d+', '', text)
text = re.sub(r'DOI:.+?\\d+', '', text)
# 4. Normalize whitespace
text = re.sub(r' {2,}', ' ', text)
text = text.strip()
# Add document information at the beginning
title_header = f"# {metadata['title']}\\n"
author_header = f"## By {metadata['author']}\\n"
source_header = f"Source: {metadata['source_url']}\\n\\n"
formatted_text = title_header + author_header + source_header + text
# Return cleaned document with metadata
result = {
"text": formatted_text,
"metadata": metadata,
"character_count": len(formatted_text),
"processing_time": kwargs.get("execution_date", "Unknown")
}
print(f"Document cleaned: {len(formatted_text)} characters")
return result
Chunk your data dynamically
The second transformation block divides the cleaned document into manageable chunks for more efficient processing. The chunks maintain context while enabling targeted information retrieval. Every segment includes metadata and prepares the content for retrieval when answering user questions. This chunking approach ensures Claude can efficiently access applicable sections of the document rather than disconnected fragments when responding to questions about the Great Attractor.
@transformer
def chunk_document(data, **kwargs):
"""
Split the cleaned document into manageable chunks with overlap
"""
# Check if data is available
if data is None or "text" not in data:
raise Exception("No cleaned document text available to chunk")
text = data["text"]
metadata = data["metadata"]
print("Chunking document with fixed size approach...")
# Set chunking parameters
chunk_size = 4000 # characters per chunk
overlap = 500 # overlap between chunks to maintain context
# Calculate how many chunks we'll need
doc_length = len(text)
estimated_chunks = (doc_length // (chunk_size - overlap)) + 1
print(f"Document length: {doc_length} characters")
print(f"Will create approximately {estimated_chunks} chunks")
# Create chunks with simple fixed-size approach
chunks = []
# Special case: if text is smaller than chunk_size, just use one chunk
if doc_length <= chunk_size:
chunks.append({
"chunk_id": 0,
"text": text,
"start_char": 0,
"end_char": doc_length,
"character_count": doc_length,
"doc_id": metadata['source_url']
})
else:
# Use a straightforward loop with explicit indices
chunk_id = 0
for i in range(0, doc_length, chunk_size - overlap):
# Calculate chunk boundaries
start = i
end = min(i + chunk_size, doc_length)
# Don't create tiny chunks at the end
if end - start < 200 and chunk_id > 0:
break
# Extract chunk text
chunk_text = text[start:end]
# Create chunk with metadata
chunks.append({
"chunk_id": chunk_id,
"text": chunk_text,
"start_char": start,
"end_char": end,
"character_count": len(chunk_text),
"doc_id": metadata['source_url']
})
chunk_id += 1
# Log progress for larger documents
if chunk_id % 5 == 0:
print(f"Created {chunk_id} chunks so far...")
# Create result
result = {
"chunks": chunks,
"chunk_count": len(chunks),
"total_characters": doc_length,
"metadata": metadata
}
print(f"Document processed into {len(chunks)} chunks")
return result
What’s next?
Stay tuned for part 2, where we’ll ask “Attractor” some interesting questions about the universe. This will be both fun to code, and fun to find out the answers to some questions about our universe. We’ll use Anthropic’s MCP libraries to interact with our knowledge document specifically leaving out general training data.

Conclusion
MCP is a significant advancement in how we can leverage AI to interact with our knowledge systems specific to a business. By creating pipelines that fetch, clean, and targeted information sources before parring them to LLMs, we can build AI assistants that provide targeted answers about the content we provide it. Building a system like “Attractor” demonstrates how we can target specific knowledge systems and use AI to help answer questions specifically about the information it is given.
Want to build a RAG pipeline using MCP methods discussed above? Schedule a free demo with Mage to get started today.



