
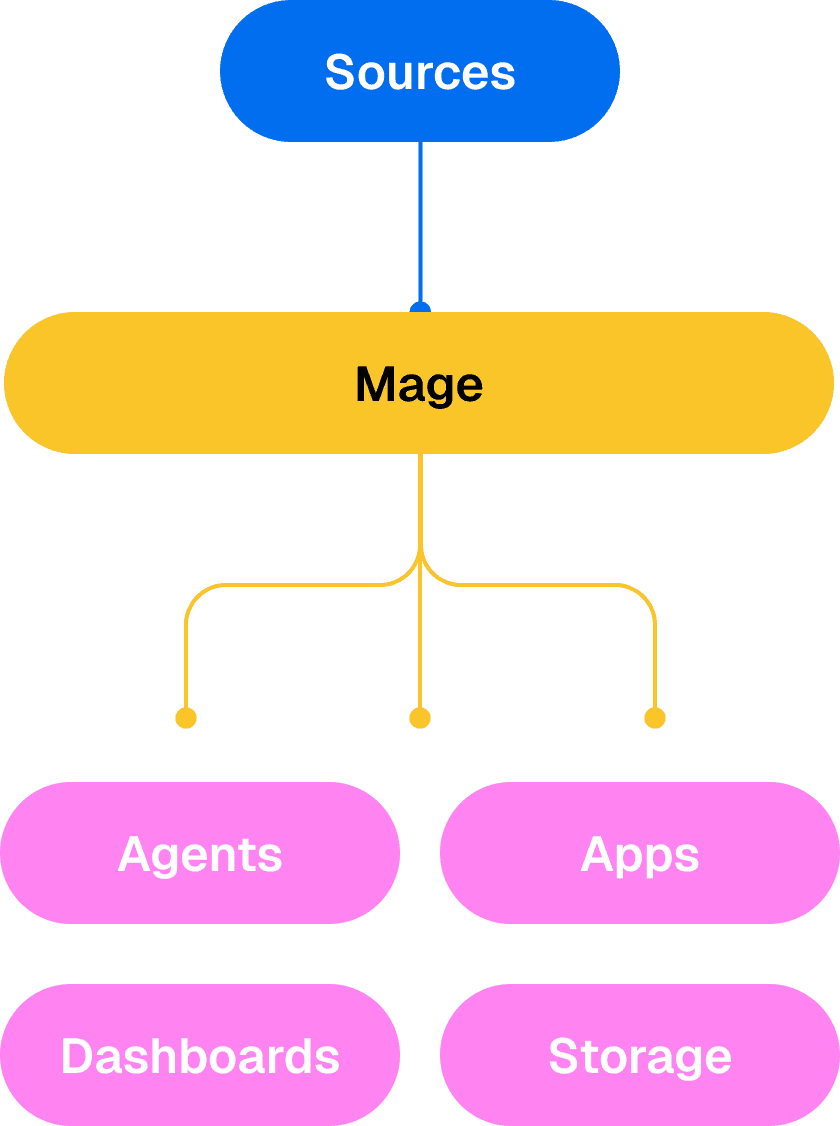
Power analytics, applications, and AI systems
Run pipelines that keep your data current and reliable in production.
Build pipelines
Across SQL, Python, R, and dbt, with full control over logic and execution
Connect data
From APIs, databases, and streams into a single, consistent system
Run continuously
On schedules or real-time triggers with managed execution
Fix and recover
Backfill data and resolve failures without rerunning entire pipelines
Reuse data
Share datasets and logic across teams without rebuilding
Power AI
Use production data to power AI systems and applications
How Mage fits into your stack
Mage sits between your data sources and the systems that use your data.


Step 1
Connect
Bring in data from your existing sources. Databases, warehouses, lakes, SaaS tools, and APIs.
Step 2
Execute
Run pipelines on your data. Use SQL, Python, R, and dbt with scheduling and managed execution.
Step 3
Deliver
Make data available for use. Publish datasets for dashboards, APIs, applications, and AI systems.
Workflows
SQL, Python, R, and dbt pipelines
Dependencies and execution order
Batch and streaming support
Ingestion
APIs, databases, warehouses
Scheduled and real-time syncs
Schema validation
Orchestration
Scheduled and event-based runs
Dependency management
Centralized run monitoring
Reliability
Backfills and partial reruns
Execution history and debugging
Testing and validation
Reuse
Reusable data and logic
Shared outputs across workflows
Version tracking over time
AI
Code generation and optimization
Natural language debugging
Run AI systems on production data
Use cases teams rely on
Running critical systems in production.



Build, run, fix, and reuse pipelines in one place
Simple to operate. Fast to recover. Built for production.

Unified execution
Run ingestion, transformation, and orchestration in one system instead of stitching tools together.

Modular runtime
Fix failures without rerunning entire pipelines. Backfill only what changed and recover quickly.

Build once, reuse everywhere
Reuse data and logic across analytics, automation, and AI systems without rebuilding.
Trusted every day by titans, unicorns, and dreamers
Faster execution, less overhead
When execution is reliable and reusable, teams move faster with less operational work.

Scale without scaling costs
Increase throughput as the business grows without adding tools or headcount.
Consolidate expensive point tools and DAG sprawl into a single execution surface
Lower total cost of ownership by reducing external orchestration and operational overhead


Iterate faster, safer
Ship changes without breaking production by making execution reproducible and recovery routine.
Promote updates through environments with controlled releases and preserved run history
Replay and partially re-run only what changed, so fixes and backfills are fast and low-risk


Watch

Deploy and run your way
Flexible deployment options designed to fit cleanly into your environment across scale, security, and performance needs.
Fastest time to value. Zero infrastructure to manage.
